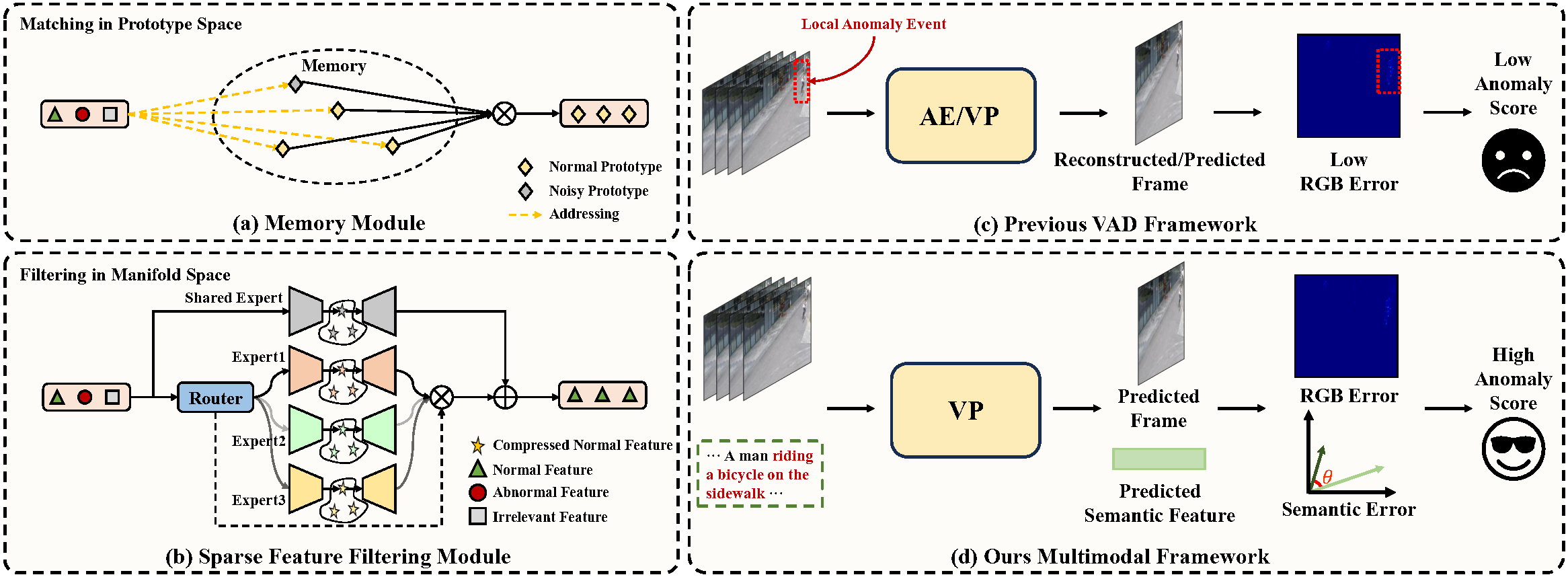
 Comparison between previous and our proposed framework. (a) Existing memory modules filter anomalous information through inflexible prototype matching. (b) Our proposed sparse feature filtering paradigm achieves better VAD performance compared to memory-based methods. (c) Existing methods measure anomaly scores through reconstruction or prediction errors, which may produce smaller errors when dealing with small objects. (d) Our proposed novel multimodal framework introduces a semantic branch that can capture subtle local anomalies through semantic errors.
Comparison between previous and our proposed framework. (a) Existing memory modules filter anomalous information through inflexible prototype matching. (b) Our proposed sparse feature filtering paradigm achieves better VAD performance compared to memory-based methods. (c) Existing methods measure anomaly scores through reconstruction or prediction errors, which may produce smaller errors when dealing with small objects. (d) Our proposed novel multimodal framework introduces a semantic branch that can capture subtle local anomalies through semantic errors.
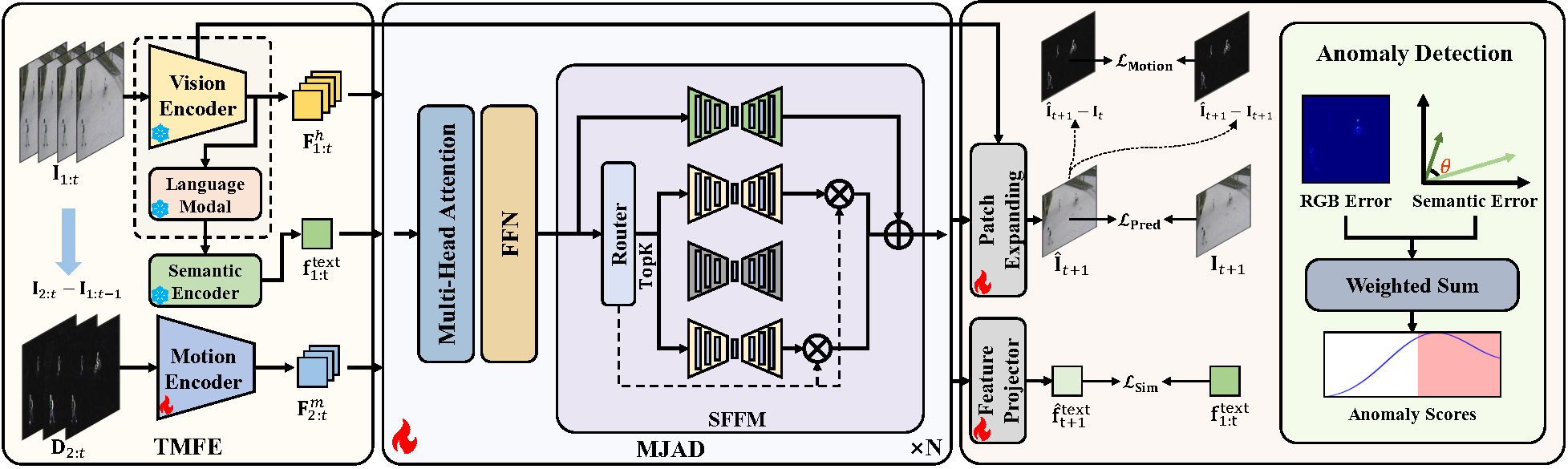 Overview of SFN-VAD. Firstly, TMFE extracts descriptions from the input clips and encodes and fuses semantic, appearance, and motion features. Secondly, MJAD performs joint decoding of the fused features to predict the next frame and semantic features. SFFM filters abnormal information to increase prediction error when anomalies occur. Finally, anomaly scores are calculated based on frame prediction errors and semantic errors.
Overview of SFN-VAD. Firstly, TMFE extracts descriptions from the input clips and encodes and fuses semantic, appearance, and motion features. Secondly, MJAD performs joint decoding of the fused features to predict the next frame and semantic features. SFFM filters abnormal information to increase prediction error when anomalies occur. Finally, anomaly scores are calculated based on frame prediction errors and semantic errors.